Linux Shell
Command History
NB : Please note that this post follows on from Linux Shell command tricks
The second of the tools available for the command line interface to a Linux shell is command History, Just like Command and file completion this set of tools provides the terminal user with a very fast method of command entry and processing.
Whenever a terminal users enters a command it is stored into a file within the users /home directory.
An example of the used file for a shell is:
For the BASH shell “/home/.bash_history”
Firstly as with many shell services it is worth noting that you can customise their configuration, for your own use if you so wish. The default setting are usually ok but if your a very heavy user such as a systems administrator however you may want to deviate somewhat from the norm/defaults.
An example of this is with the configuration of a shells history functions.
If you use the BASH shell, your main configuration file is /home/.bashrc and as default it contains the following lines for the bash history functions.
——————————————————————————-
/home/.bashrc
# don’t put duplicate lines or lines starting with space in the history.
# See bash(1) for more options
HISTCONTROL=ignoreboth
# append to the history file, don’t overwrite it
shopt -s histappend
# for setting history length see HISTSIZE and HISTFILESIZE in bash(1)
HISTSIZE=1000
HISTFILESIZE=2000
——————————————————————————-
You can take the following facts out of looking through these lines of code !!
1. By default lines that begin with spaces or are already to be found in /home/.bash_history, will not be written to the file.
2. By default all commands during every shell session with be added to the /home/.bash_history file, not just the commands entered during the current and thus this, shell session.
3.. There is a shell history command called “shopt” you can look up in the man pages, in order to understand how it can be used to configure the shells history functions.
4.. The two variable’s HISTSIZE and HISTFILESIZE exist in order to limit the number of individual commands stored and/or the total size of the /home/.bash_history file.
These configuration options can best be explained as follows along with other options not configured as default :
——————————————————————————-
Better shell history
By default, the Bash shell keeps the history of your most recent session in the .bash_history file, and the commands you’ve issued in your current session are also available with a history call. These defaults are useful for keeping track of what you’ve been up to in the shell on any given machine, but with disks much larger and faster than they were when Bash was designed, a little tweaking in your .bashrc file can record history more permanently, consistently, and usefully.
Append history instead of rewriting it
History append option
You should start by setting the histappend option, which will mean that when you close a session, your history will be appended to the .bash_history file rather than overwriting what’s in there.
shopt -s histappend
Allow a larger history file
The default maximum number of commands saved into the .bash_history file is a rather meager 500. If you want to keep history further back than a few weeks or so, you may as well bump this up by explicitly setting $HISTSIZE to a much larger number in your .bashrc. We can do the same thing with the $HISTFILESIZE variable.
HISTFILESIZE=1000000
HISTSIZE=1000000
The man page for Bash says that HISTFILESIZE can be unset to stop truncation entirely, but unfortunately this doesn’t work in .bashrc files due to the order in which variables are set; it’s therefore more straightforward to simply set it to a very large number.
If you’re on a machine with resource constraints, it might be a good idea to occasionally archive old .bash_history files to speed up login and reduce memory footprint.
Don’t store specific lines
You can prevent commands that start with a space from going into history by setting $HISTCONTROL to ignorespace. You can also ignore duplicate commands, for example repeated du calls to watch a file grow, by adding ignoredups. There’s a shorthand to set both in ignoreboth.
HISTCONTROL=ignoreboth
You might also want to remove the use of certain commands from your history, whether for privacy or readability reasons. This can be done with the $HISTIGNORE variable. It’s common to use this to exclude ls calls, job control builtins like bg and fg, and calls to history itself:
HISTIGNORE=’ls:bg:fg:history’
Record timestamps
If you set $HISTTIMEFORMAT to something useful, Bash will record the timestamp of each command in its history. In this variable you can specify the format in which you want this timestamp displayed when viewed with history. I find the full date and time to be useful, because it can be sorted easily and works well with tools like cut and awk.
HISTTIMEFORMAT=’%F %T ‘
Use one command per line
To make your .bash_history file a little easier to parse, you can force commands that you entered on more than one line to be adjusted to fit on only one with the cmdhist option:
shopt -s cmdhist
Store history immediately
By default, Bash only records a session to the .bash_history file on disk when the session terminates. This means that if you crash or your session terminates improperly, you lose the history up to that point. You can fix this by recording each line of history as you issue it, through the $PROMPT_COMMAND variable:
PROMPT_COMMAND=’history -a’
——————————————————————————-
Basic shell history usage
1.. Retrieving a command
The most basic way to retrieve a command from the history system is to use the UP arrow key on the Keyboard, doing so repeatedly will scroll back through your command history until you reach the wanted command. If you go past the wanted command just press the down key !
The Ctrl+P and Ctrl+N keys perform the same function respectfully
Search history for a command
The above method works well if your wanted command was entered into history with-in the last few commands but not so well if it was entered a few days or weeks ago!
In order to retrieve older commands you can search for them in the history system as follows:
By pressing Ctrl+R and typing a few characters of the command you want, you will be able to search back through the shells command history. The characters should build up to form a unique part of the command, they need not be at the start of the command but can form any part of it, i.e. a file name or ip address. If you cannot enter a unique part of a command then by pressing Ctrl+R again you will be able to scroll through all commands that do contain the characters you have entered for the search.
NB : Ctrl-S performs a forward search if you find yourself anywhere before the end of the history file, having already performed a search with Ctrl-R for example. On some systems Ctrl-S my hang the terminal , by pressing Ctrl+Q you will free up the terminal again, the command “stty -ixon” should prevent this hanging from taking place again.
Command editor
When you have retrieved a command from history, just like when you are entering a command for the first time, you will without even realising it be using the keyboard instructions and command sets from one of two possible text editors (EMACS or VI), most Linux distributions use EMACS as default but you can change to VI/VIM and back again as follows !
enter “set -o vi” or “set -o emacs ” from the terminal prompt , you can also enter this command into you users profile configuration file /home/.profile.
NB : You can find many web pages that detail the syntax of both editors and will need to know this syntax to pass these Linux exams.
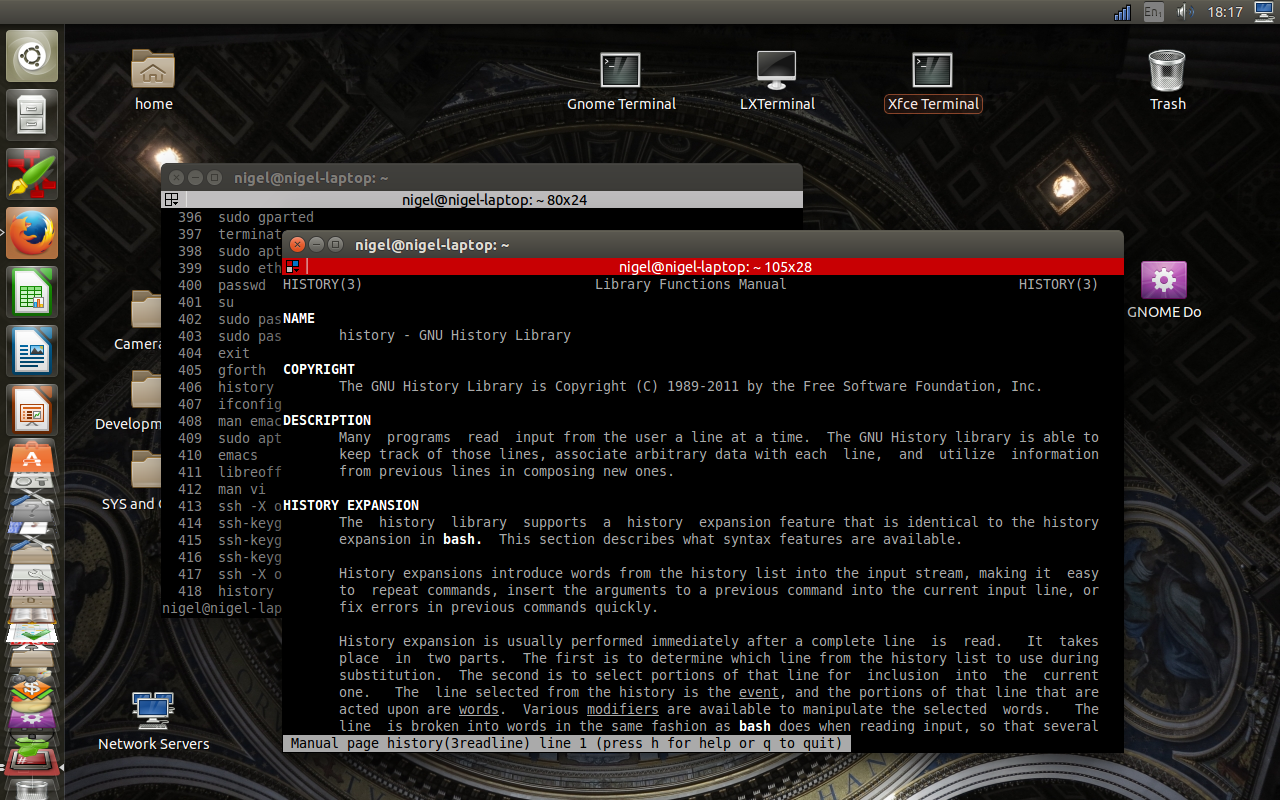
history command
by typing “history” at the command prompt, you will see a full list of all your history file commands along this their reference number.
i.e. 419 ls -al ./.h*
The following command short cuts can be used quickly, to both retrieve a command using its Ref number or retrieve the very last command in the history file as a reference point.
!! = Retrieve and execute the very last command
!(x) = Retrieve and execute the command with Ref number(x)
!-(x) = Retrieve and execute the command at the (final history ref number (x) – (x)
Clearing your command shell history
To clear you command history execute the following command
history -c
——————————————————————————-
Bash history expansion
Setting the Bash option histexpand allows some convenient typing shortcuts using Bash history expansion. The option can be set with either of these:
$ set -H
$ set -o histexpand
It’s likely that this option is already set for all interactive shells, as it’s on by default. The manual, man bash, describes these features as follows:
-H Enable ! style history substitution. This option is on
by default when the shell is interactive.
You may have come across this before, perhaps to your annoyance, in the following error message that comes up whenever ! is used in a double-quoted string, or without being escaped with a backslash:
$ echo “Hi, this is Tom!”
bash: !”: event not found
If you don’t want the feature and thereby make ! into a normal character, it can be disabled with either of these:
$ set +H
$ set +o histexpand
History expansion is actually a very old feature of shells, having been available in csh before Bash usage became common.
This article is a good followup to Better Bash history, which among other things explains how to include dates and times in history output, as these examples do.
Basic history expansion
Perhaps the best known and most useful of these expansions is using !! to refer to the previous command. This allows repeating commands quickly, perhaps to monitor the progress of a long process, such as disk space being freed while deleting a large file:
$ rm big_file &
[1] 23608
$ du -sh .
3.9G .
$ !!
du -sh .
3.3G .
It can also be useful to specify the full filesystem path to programs that aren’t in your $PATH:
$ hdparm
-bash: hdparm: command not found
$ /sbin/!!
/sbin/hdparm
In each case, note that the command itself is printed as expanded, and then run to print the output on the following line.
History by absolute index
However, !! is actually a specific example of a more general form of history expansion. For example, you can supply the history item number of a specific command to repeat it, after looking it up with history:
$ history | grep expand
3951 2012-08-16 15:58:53 set -o histexpand
$ !3951
set -o histexpand
You needn’t enter the !3951 on a line by itself; it can be included as any part of the command, for example to add a prefix like sudo:
$ sudo !3850
If you include the escape string \! as part of your Bash prompt, you can include the current command number in the prompt before the command, making repeating commands by index a lot easier as long as they’re still visible on the screen.
History by relative index
It’s also possible to refer to commands relative to the current command. To subtitute the second-to-last command, we can type !-2. For example, to check whether truncating a file with sed worked correctly:
$ wc -l bigfile.txt
267 bigfile.txt
$ printf ‘%s\n’ ’11,$d’ w | ed -s bigfile.txt
$ !-2
wc -l bigfile.txt
10 bigfile.txt
This works further back into history, with !-3, !-4, and so on.
Expanding for historical arguments
In each of the above cases, we’re substituting for the whole command line. There are also ways to get specific tokens, or words, from the command if we want that. To get the first argument of a particular command in the history, use the !^ token:
$ touch a.txt b.txt c.txt
$ ls !^
ls a.txt
a.txt
To get the last argument, add !$:
$ touch a.txt b.txt c.txt
$ ls !$
ls c.txt
c.txt
To get all arguments (but not the command itself), use !*:
$ touch a.txt b.txt c.txt
$ ls !*
ls a.txt b.txt c.txt
a.txt b.txt c.txt
This last one is particularly handy when performing several operations on a group of files; we could run du and wc over them to get their size and character count, and then perhaps decide to delete them based on the output:
$ du a.txt b.txt c.txt
4164 a.txt
5184 b.txt
8356 c.txt
$ wc !*
wc a.txt b.txt c.txt
16689 94038 4250112 a.txt
20749 117100 5294592 b.txt
33190 188557 8539136 c.txt
70628 399695 18083840 total
$ rm !*
rm a.txt b.txt c.txt
These work not just for the preceding command in history, but also absolute and relative command numbers:
$ history 3
3989 2012-08-16 16:30:59 wc -l b.txt
3990 2012-08-16 16:31:05 du -sh c.txt
3991 2012-08-16 16:31:12 history 3
$ echo !3989^
echo -l
-l
$ echo !3990$
echo c.txt
c.txt
$ echo !-1*
echo c.txt
c.txt
More generally, you can use the syntax !n:w to refer to any specific argument in a history item by number. In this case, the first word, usually a command or builtin, is word 0:
$ history | grep bash
4073 2012-08-16 20:24:53 man bash
$ !4073:0
man
What manual page do you want?
$ !4073:1
bash
You can even select ranges of words by separating their indices with a hyphen:
$ history | grep apt-get
3663 2012-08-15 17:01:30 sudo apt-get install gnome
$ !3663:0-1 purge !3663:3
sudo apt-get purge gnome
You can include ^ and $ as start and endpoints for these ranges, too. 3* is a shorthand for 3-$, meaning “all arguments from the third to the last.”
Expanding history by string
You can also refer to a previous command in the history that starts with a specific string with the syntax !string:
$ !echo
echo c.txt
c.txt
$ !history
history 3
4011 2012-08-16 16:38:28 rm a.txt b.txt c.txt
4012 2012-08-16 16:42:48 echo c.txt
4013 2012-08-16 16:42:51 history 3
If you want to match any part of the command line, not just the start, you can use !?string?:
$ !?bash?
man bash
Be careful when using these, if you use them at all. By default it will run the most recent command matching the string immediately, with no prompting, so it might be a problem if it doesn’t match the command you expect.
Checking history expansions before running
If you’re paranoid about this, Bash allows you to audit the command as expanded before you enter it, with the histverify option:
$ shopt -s histverify
$ !rm
$ rm a.txt b.txt c.txt
This option works for any history expansion, and may be a good choice for more cautious administrators. It’s a good thing to add to one’s .bashrc if so.
If you don’t need this set all the time, but you do have reservations at some point about running a history command, you can arrange to print the command without running it by adding a :p suffix:
$ !rm:p
rm important-file
In this instance, the command was expanded, but thankfully not actually run.
Substituting strings in history expansions
To get really in-depth, you can also perform substitutions on arbitrary commands from the history with !!:gs/pattern/replacement/. This is getting pretty baroque even for Bash, but it’s possible you may find it useful at some point:
$ !!:gs/txt/mp3/
rm a.mp3 b.mp3 c.mp3
If you only want to replace the first occurrence, you can omit the g:
$ !!:s/txt/mp3/
rm a.mp3 b.txt c.txt
Stripping leading directories or trailing files
If you want to chop a filename off a long argument to work with the directory, you can do this by adding an :h suffix, kind of like a dirname call in Perl:
$ du -sh /home/tom/work/doc.txt
$ cd !$:h
cd /home/tom/work
To do the opposite, like a basename call in Perl, use :t:
$ ls /home/tom/work/doc.txt
$ document=!$:t
document=doc.txt
Stripping extensions or base names
A bit more esoteric, but still possibly useful; to strip a file’s extension, use :r:
$ vi /home/tom/work/doc.txt
$ stripext=!$:r
stripext=/home/tom/work/doc
To do the opposite, to get only the extension, use :e:
$ vi /home/tom/work/doc.txt
$ extonly=!$:e
extonly=.txt
Quoting history
If you’re performing substitution not to execute a command or fragment but to use it as a string, it’s likely you’ll want to quote it. For example, if you’ve just found through experiment and trial and error an ideal ffmpeg command line to accomplish some task, you might want to save it for later use by writing it to a script:
$ ffmpeg -f alsa -ac 2 -i hw:0,0 -f x11grab -r 30 -s 1600×900 \
> -i :0.0+1600,0 -acodec pcm_s16le -vcodec libx264 -preset ultrafast \
> -crf 0 -threads 0 “$(date +%Y%m%d%H%M%S)”.mkv
To make sure all the escaping is done correctly, you can write the command into the file with the :q modifier:
$ echo ‘#!/usr/bin/env bash’ >ffmpeg.sh
$ echo !ffmpeg:q >>ffmpeg.sh
In this case, this will prevent Bash from executing the command expansion “$(date … )”, instead writing it literally to the file as desired. If you build a lot of complex commands interactively that you later write to scripts once completed, this feature is really helpful and saves a lot of cutting and pasting.
————————————————-
History security footnote !!
Most likely system security should not be as a foot-note! but the following is a very important detail !!
Never enter passwords on the command line, as part of a command. Some shell commands allow you to do so but note that they will store these passwords into the history file as ascii text, so anyone who has access to your history file can see your passwords !!.
Many commands will prompt you for a password, if they need one to function, the password you enter in this way is never stored in your history file, so if you can always operate in this mode of security !!!
If you absolutely need to give your password as part of a command, then clear your history after you enter the command as follows:
history -c # clear your command history !